
Note: This content was originally published at the Simple AWS newsletter. Understand the Why behind AWS Solutions. Subscribe for free! 3000 engineers and tech experts already have.
Use case: Microservices design
Scenario
We have an online learning platform built as a monolithic application, which enables users to browse and enroll in a variety of courses, access course materials such as videos, quizzes, and assignments, and track their progress throughout the courses. The application is deployed in Amazon ECS as a single service that's scalable and highly available.
As the app has grown, we've noticed that content delivery becomes a bottleneck during normal operations. Additionally, changes in the course directory resulted in some bugs in progress tracking. To deal with these issues, we decided to split the app into three microservices: Course Catalog, Content Delivery, and Progress Tracking.
Out of scope (so we don't lose focus)
Authentication/authorization: When I say “users” I mean authenticated users. We could use Cognito for this. Next week's issue will be about Cognito.
User registration and management: Same as above.
Payments: Since our courses are so awesome, we should charge for them. We could use a separate microservice that integrates with a payment processor such as Stripe.
Caching and CDN: We should use CloudFront to cache the content, to reduce latency and costs. We'll do that in a future issue, let's focus on the microservices right now.
Frontend: Obviously, we need a frontend for our app. Frontend code is clearly out of scope for a newsletter about AWS, but we could say a few interesting things about serving the frontend from S3, server-side rendering, and comparing with Amplify. That's a topic for a future issue though.
Database design: Assume our database is properly designed. We talked about the technical nuances of DynamoDB in the past, but an issue entirely dedicated to designing a database for DynamoDB is an interesting idea.
Admin: Someone has to create the courses, upload the content, course metadata, etc. The operations to do that fall under the scope of our microservices, but I feared it would grow too complex, so I cut those features out.
Services
ECS: Our app is already deployed in ECS as a single ECS Service, we're going to split it into 3 microservices and deploy each as an ECS Service. Nothing new under the sun, but if you're not familiar with ECS check our previous issue.
DynamoDB: Our database for this example.
API Gateway: Used to expose each microservice.
Elastic Load Balancer: To balance traffic across all the tasks.
S3: Storage for the content (video files) of the courses.
ECR: Just a Docker registry.
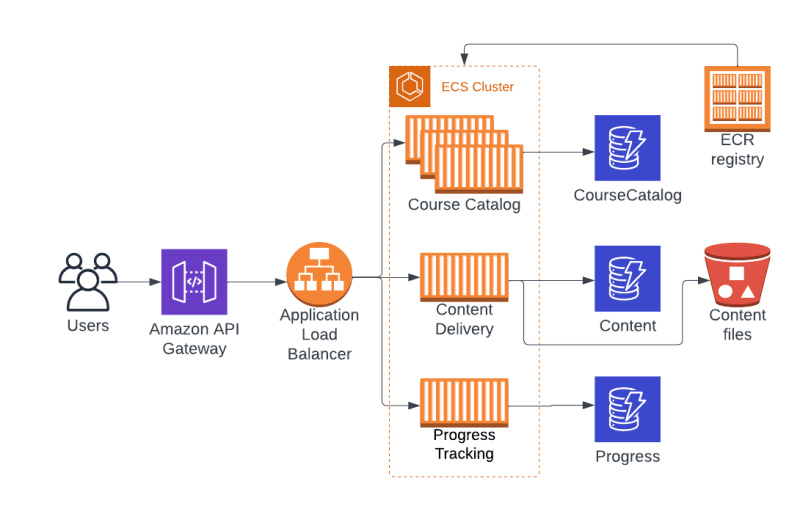
Solution step by step
Identify the microservices
Analyze the monolithic application, focusing on the course catalog, content delivery, and progress tracking functionalities. Based on these functionalities, outline the responsibilities for each microservice:
Course Catalog: manage courses and their metadata.
Content Delivery: handle storage and distribution of course content.
Progress Tracking: manage user progress through courses.
Define the APIs for each microservice
Design the API endpoints for each microservice:
-
Course Catalog:
- GET /courses: list all courses
- GET /courses/:id get a specific course
-
Content Delivery:
- GET /content/:id get a pre-signed URL for a specific course content
-
Progress Tracking:
- GET /progress/:userId: get a user's progress
- PUT /progress/:userId/:courseId: update a user's progress for a specific course
Create separate repositories and projects for each microservice
Set up individual repositories and Node.js projects for Course Catalog, Content Delivery, and Progress Tracking microservices. Structure the projects using best practices, with separate folders for routes, controllers, and database access code. You know the drill.
Separate the code
Refactor the monolithic application code, moving the relevant functionality for each microservice into its respective project:
Move the code related to managing courses and their metadata into the Course Catalog microservice project.
Move the code related to handling storage and distribution of course content into the Content Delivery microservice project.
Move the code related to managing user progress through courses into the Progress Tracking microservice project.
The code may not be as clearly separated as you might want. In that case, first separate it within the same project, test those changes, then move the code to the microservices.
Separate the data
Create separate Amazon DynamoDB tables for each microservice:
CourseCatalog: stores course metadata, such as title, description, and content ID.
Content: stores content metadata, including content ID, content type, and S3 object key.
Progress: stores user progress, with fields for user ID, course ID, and progress details.
Update the database access code in each microservice to interact with its specific table.
If you're doing this for a database which already has data, you can export it to S3, use Glue to filter the data, and then import it back to DynamoDB.
If the system is live, it gets trickier:
First, add a timestamp to your data if you don't have one already.
Next, create the new tables.
Then set up DynamoDB Streams to replicate all writes to the corresponding table.
Then copy the old data, either with a script or with an S3 export + Glue (don't use the DynamoDB import, it only works for new tables, write the data manually instead). Make sure this can handle duplicates.
Finally, switch over to the new tables.
Configure API Gateway
Set up Amazon API Gateway to manage and secure the API endpoints for each microservice:
Create an API Gateway resource for each microservice (Course Catalog, Content Delivery, and Progress Tracking).
Apply request validation to ensure incoming requests are well-formed.
Deploy the microservices to ECS
Write Dockerfiles for each microservice, specifying the base Node.js image, copying the source code, and setting the appropriate entry point.
Build and push the Docker images to Amazon Elastic Container Registry (ECR) for each microservice.
Create separate task definitions in Amazon ECS for each microservice, specifying the required CPU, memory, environment variables, and the ECR image URLs.
Create ECS services for each microservice, associating them with the corresponding task definitions and API Gateway endpoints.
Update the frontend
Modify the frontend code to work with the new microservices-based architecture. Update API calls to use the corresponding API Gateway endpoints for Course Catalog, Content Delivery, and Progress Tracking microservices.
Test the new architecture
Thoroughly test the transformed application, covering various user scenarios such as:
Logging in and browsing the course catalog.
Accessing course content using the pre-signed URLs generated by the Content Delivery microservice.
Tracking user progress in a course and retrieving progress information through the Progress Tracking microservice.
Validate that the application works as expected and meets performance, security, and reliability requirements.
Solution explanation
Identify the microservices
I kind of did that for you on this issue, but you should never rush this, take your time and get it right.
There's two ways to split microservices:
Vertical slices: Each microservice solves a particular use case or set of tightly-related use cases. You add services as you add features, and each user interaction goes through the minimum possible number of services (ideally only 1). This means features are an aspect of decomposition. Code reuse is achieved through shared libraries.
Functional services: Each service handles one particular step, integration, state, or thing. System behavior is an emergent property, resulting from combining different services in different ways. Each user interaction invokes multiple services. New features don't need entirely new services. Features are an aspect of integration, not decomposition. Code reuse is often achieved through invoking another service.
I went for vertical slices, because it's simpler to understand and easier to realize for simpler systems. Plus, in this case we didn't even need to deal with service discovery. The drawback is that if your system does 200 different things, it'll need at least 200 services.
By the way, don't even think about migrating from one microservice strategy to the other one. It's much easier to drop the whole system and start from scratch.
Define the APIs for each microservice
This is pretty straightforward, since they're the same endpoints that we had for the monolith. If we were using functional services, it would get a lot more difficult, since you'd need to understand what service A needs from service B.
Remember that the only way into a microservice (and that includes its data) is through the service's API, so design this wisely. Check out Fowler's post on consumer-driven contracts for some deep insights.
Create separate repositories and projects for each microservice
Basically, keep separate microservices seprate.
You could use a monorepo, where the whole codebase is in a single git repository but services are still deployed separately. This works well, but it's a bit harder to pull off.
Separate the code
First, refactor as needed until you can copy-paste the implementation code from your monolith to your services (but don't copy it just yet). Then test the refactor. Finally, do the copy-pasting.
Separate the data
The difference between a service and a microservice is the bounded context. Each microservice owns its model, including the data, and the only way to access that model (and the database that stores it) is through that service's API.
We could technically implement this without enforcing it, and we could even enforce it with DynamoDB's field-level permissions. But we couldn't scale the services independently using a single table, since capacity is assigned per table.
DynamoDB tables are easy to create and manage (other than defining the data model). In a relational database we would need to consider the tradeoff between having to manage (and pay for) one DB cluster per microservice, or separating per table + DB user or per database in the same cluster, losing the ability to scale the data stores independently. Aurora Serverless is a viable option as well, though it's not cheap for a continuously running database.
Configure API Gateway
This is actually a best practice, but I added it as part of the solution because you're going to need it for authentication. We already discussed the benefits of API Gateway and how to implement it.
Deploy the microservices to ECS
If you already deployed the monolith, I assume you know how to deploy the services. If not, check the newsletter issue about migrating from EC2 to ECS.
Update the frontend
For simplicity, I assume this means updating the frontend code with the new URLs for your services.
If you were already using the same paths in API Gateway, that's what you should update instead. See? The benefits of API Gateway!
Test the new architecture
You build it, you deploy it, you test it, and only then you declare that it works.
Discussion
There's a lot to say about microservices (heck, I just wrote 3000 words on the topic), but the main point is that you don't need microservices (for 99% of apps).
Microservices exist to solve a specific problem: problems in complex domains require complex solutions, which become unmanageable due to the size and complexity of the domain itself. Microservices (when done right) split that complex domain into simpler bounded contexts, thus encapsulating the complexity and reducing the scope of changes (that's why they change independently). They also add complexity to the solution, because now you need to figure out where to draw the boundaries of the contexts, and how the microservices interact with each other, both at the domain level (complex actions that span several microservices) and at the technical level (service discovery, networking, permissions).
So, when do you need microservices? When the reduction in complexity of the domain outweighs the increase in complexity of the solution.
When do you not need microservices? When the domain is not that complex. In that case, use regular services, where the only split is in the behavior (i.e. backend code). Or stick with a monolith, Facebook does that and it works pretty well, at a size we can only dream of.
By the way, here's what a user viewing a course looks like before the split:
The user sends a login request with their credentials to the monolithic application.
The application validates the credentials and, if valid, generates an authentication token for the user.
The user sends a request to view a course, including the authentication token in the request header.
The application checks the authentication token and retrieves the course details from the Courses table in DynamoDB.
The application retrieves the course content metadata from the Content table in DynamoDB, including the S3 object key.
Using the S3 object key, the application generates a pre-signed URL for the course content from Amazon S3.
The application responds with the course details and the pre-signed URL for the course content.
The user's browser displays the course details and loads the course content using the pre-signed URL.
And here's what it looks like after the split:
The user sends a login request with their credentials to the authentication service (not covered in the previous microservices example).
The authentication service validates the credentials and, if valid, generates an authentication token for the user.
The user sends a request to view a course, including the authentication token in the request header, to the Course Catalog microservice through API Gateway.
The Course Catalog microservice checks the authentication token and retrieves the course details from its Course Catalog table in DynamoDB.
The Course Catalog microservice responds with the course details.
The user's browser sends a request to access the course content, including the authentication token in the request header, to the Content Delivery microservice through API Gateway.
The Content Delivery microservice checks the authentication token and retrieves the course content metadata from its Content table in DynamoDB, including the S3 object key.
Using the S3 object key, the Content Delivery microservice generates a pre-signed URL for the course content from Amazon S3.
The Content Delivery microservice responds with the pre-signed URL for the course content.
The user's browser displays the course details and loads the course content using the pre-signed URL.
Best Practices
Operational Excellence
Centralized logging: You're basically running 3 apps. Store the logs in the same place, such as CloudWatch Logs (which ECS automatically configures for you).
Distributed tracing: These three services don't call each other, but in a real microservices app it's a lot more common for that to happen. In those cases, following the trail of calls becomes rather difficult. Use X-Ray to make it a lot simpler.
Security
Least privilege: It's not enough to not write the code to access another service's data, you should also enforce it via IAM permissions. Your microservices should each use a different IAM role, that lets each access its own DynamoDB table, not *.
Networking: If a service doesn't need network visibility, it shouldn't have it. Enforce it with security groups.
Zero trust: The idea is to not trust agents inside a network, but instead authenticate at every stage. Exposing your services through API Gateway gives you an easy way to do this. Yes, you should do this even when exposing them to other services.
Reliability
Circuit breakers: User calls Service A, Service A calls Service B, Service B fails, the failure cascades, everything fails, your car is suddenly on fire (just go with it), your boss is suddenly on fire (is that a bad thing?), everything is on fire. Circuit breakers act exactly like the electric versions: They prevent a failure in one component from affecting the whole system. I'll let Fowler explain.
Consider different scaling speeds: If Service A depends on Service B, consider that Service B scales independently, which could mean that instances of Service B are not started as soon as Service A gets a request. Service B could be implemented in a different platform (EC2 Auto Scaling vs Lambda), which scales at a different speed. Keep that in mind for service dependencies, and decouple the services when you can.
Performance Efficiency
Scale services independently: Your microservices are so independent that even their databases are independent! You know what that means? You can scale them at will!
Rightsize ECS tasks: Now that you split your monolith, it's time to check the resource usage of each microservice, and fine-tune them independently.
Rightsize DynamoDB tables: Same as above, for the database tables.
Cost Optimization
Optimize capacity: Determine how much capacity each service needs, and optimize for it. Get a savings plan for the baseline capacity.
Consider different platforms: Different microservices have different needs. A user-facing microservice might need to scale really fast, at the speed of Fargate or Lambda. A service that only processes asynchronous transactions, such as a payments-processing service, probably doesn't need to scale as fast, and can get away with an Auto Scaling Group (which is cheaper per compute time). A batch processing service could even use Spot Instances! Every service is independent, so don't limit yourself.
Do consider the increased management efforts: It's easier (thus cheaper) to manage 10 Lambda functions than to manage 5 Lambda functions, 1 ECS cluster and 2 Auto Scaling Groups.
Understand the Why behind AWS Solutions.
Join over 3000 devs, tech leads, and experts learning how to architect cloud solutions, not pass exams, with the Simple AWS newsletter.
- Real-world scenarios
- The Why behind solutions
- How to apply best practices
If you'd like to know more about me, you can find me on LinkedIn or at www.guilleojeda.com





Top comments (1)
Thank you, I would try this